Steven R. Loomis2023-10-07T14:43:49.137Zhttps://srl295.github.io/Steven R. LoomisHexoTypeScript Array funhttps://srl295.github.io/2023/10/07/ts-array-fun/2023-10-07T16:19:34.000Z2023-10-07T14:43:49.137ZWhat’s in an Array? I ran into an unexpected TypeScript (or perhaps JavaScript) issue. Yes, I know, yet another.
Here’s how it works. Names have been changed to protect the author of this pr.
Starting out
Let’s say you want an array class. Not just any array, a special array.
1 2 3 4 5 6 7 8 9 10
import"node:console";
classSplitArrayextendsArray<String> { constructor(strs : string, sep : string) { super(); for(const s of strs.split(sep)) { this.push(s); } } }
Not a lot to see here. It's a special array class, we have a special constructor to get the data just right.
… > q.toString() /dev/null/arrays.ts:6 for(const s of strs.split(sep)) { ^
TypeError: strs.split is not a function or its return value is not iterable at SplitArray (/dev/null/arrays.ts:6:29) at SplitArray.map (<anonymous>) at SplitArray.toString (/dev/null/arrays.ts:12:21) at Object.<anonymous> (/dev/null/arrays.ts:21:15) …
Huh? Line 6 is the constructor. Why are we constructing this object, yet again? I was just trying to add a little toString()…
The insanity check bounces
Maybe the map function is too complicated. Let’s just change it to this.map(q => q) to see if it works at all. Nope.
Debugging shows that strs has the value of 3. As in, the number.
We also could have contained the Array as a property, instead of subclassing.
The tl;dr (now that you’ve perhaps already read it) is: Use caution when overriding Array constructors. Consider having an array instead of being one.
]]>
<p>What’s in an Array? I ran into an unexpected TypeScript (or perhaps JavaScript) issue. Yes, I know, yet another.</p>
<p>Here’s how it wor
Progress on LDML Keyman Keyboardshttps://srl295.github.io/2022/12/29/ldml-keyman-kbd-progress/2022-12-30T00:28:09.000Z2022-12-30T00:43:41.754ZThis is a follow-on to the end-of-year Code Hive Tx 2022 year end report, so read that first if you would like some greater context.
The purpose of this post is to give some updated progress on the status of implementing CLDR (LDML format) keyboards in SIL Keyman.
Basic Test
In Keyman, there’s a sample XML file named basic.xml. It’s not a “real” keyboard, but instead a unit test file. In fact, as a keyboard it has only two keys. Here is the file in part (skipping aspects not relevant to this test):
The keyboard conforms to a certain CLDR version. We’re still in unreleased territory, so for now the version is techpreview.
The “key bag” has two named keys.
The first is named hmaqtugha and is the Maltese ħ, known as “H Maqtugħa” 1 that is “cut H” as opposed to the ordinary H (akka). By the way, the character ħ is Unicode U+0127, which is decimal 295. And now you know the origin of that number in my username.
The second key is named that because it is the word meaning “that” in Khmer (Cambodian), ថា.
There is a single hardware layer, with a single row. That row is the one which in a US Keyboard begins with backquote, 1, 2, 3, etc.
So one would expect, using this keyboard, to see ħ if the backquote key is pressed, and to see ថា if the number 1 is pressed.
Compiling and Packaging
I used the in-development Keyman compiler tool, kmc, which turned the above XML into a small basic.kmx file. The tool is written in TypeScript and so is easy to run from any command line via Node.js.
Next, I hand-built a .kps file, or rather, copied-and-pasted an existing one to suit my needs. This is a Keyman "package source", basically a manifest of which files will end up on the user’s desk. The most exciting part of this xml file is reproduced below:
… <Files> <File> <Name>..\build\basic-xml.kmx</Name> <Description>Keyboard Basic LDML</Description> <CopyLocation>0</CopyLocation> <FileType>.kmx</FileType> </File> … </Files> <Keyboards> <Keyboard> <Name>Basic LDML</Name> <ID>basic-xml</ID><!-- MUST MATCH the .kmx name !! --> <Version>1.3</Version> <Languages> <LanguageID="en">Anguish Languish</Language> </Languages> </Keyboard> </Keyboards>
As the comment says, the <ID> must match the .kmx file. In any event, these files were packaged into a basic_ldml.kmp file, which, like a .jar and many other such packages, is really a zipfile in disguise.
Now I have a Keyman packaged keyboard, just like any of the thousands of other Keyman-format keyboards in the world.
Firing it up on Linux
Well, sort of. We actually need a Keyman engine and core which knows how to deal with this new format keyboard. The LDML format isn't compiled into the existing Keyman binary format, but it is in fact a new variant of the format.
At the moment, compiling the engine and core for Linux, specifically for a separate VM, seemed to be the easiest path to use the new keyboard. Of course, I expect that someday all copies of Keyman will include this support.
I chose an Ubuntu 22.04 VM and was able to compile Keyman without much trouble. Keyman for Linux has a Python UI for its configuration, and hooks into the ibus input framework.
Installation
Installing was easy, I just clicked Install in the km-config UI and chose the .kmp file.
Once installed, I could select the new keyboard from the system menu.
Trying it out
Now we’re ready to actually type in gedit!
It’s hard to say a lot with just these two characters. But it is a start.
Maltese, yet again
Let’s now try to work with a real keyboard, specifically MSA 100:2002 available from MCCAA. The hardware here is a Sirap K366P.
In the keyboard-preview branch of CLDR, the mt.xml file is available as an example file. It reads in part:
<keys> <importbase="cldr"path="techpreview/key-Zyyy-punctuation.xml"/> … <keyid="c-tikka"to="ċ" /> <keyid="C-tikka"to="Ċ" /> <keyid="g-tikka"to="ġ" /> <keyid="G-tikka"to="Ġ" /> <keyid="h-maqtugha"to="ħ" /> <keyid="H-maqtugha"to="Ħ" /> <keyid="z-tikka"to="ż" /> <keyid="Z-tikka"to="Ż" /> … </keys> … <layersform="hardware"hardware="iso"> <layermodifier="none"> <rowkeys="c-tikka 1 2 3 4 5 6 7 8 9 0 minus equals" /> <rowkeys="q w e r t y u i o p g-tikka h-maqtugha" /> <rowkeys="a s d f g h j k l semi-colon hash" /> <rowkeys="z-tikka z x c v b n m comma period slash" /> <rowkeys="space" /> </layer> </layers>
I used an in-progress pull request to flatten the 'import' statement out, as I have not implemented that in kmc yet, and also pulled in the 'implied' keys such as:
The exact file I compiled for this is here if you wish to see it. It had to be slightly edited due a couple of unimplemented features.
Typing Maltese with a hardware keyboard
And it works also! 2 Roughly, the above says “Health… Good Morning” which is, all things considered, not a bad way to end this year’s blog posts.
Footnotes
1.In preparing these articles, I found that I had misspelled “maqtugħa” from memory everywhere. There are PRs in progress to correct this. ↩
2.Ok: The space bar isn't working, nor the shift layers. But, it is a start. ↩
]]>
<p>This is a follow-on to the end-of-year <a href="/2022/12/26/code-hive-2022/" title="Code Hive Tx 2022">Code Hive Tx 2022</a> year end rep
Code Hive Tx in 2022https://srl295.github.io/2022/12/26/code-hive-2022/2022-12-26T20:00:00.000Z2022-12-29T22:40:05.611ZWell, it was 2.5 years since I posted the srl.next article and clearly a lot has gone on.
We’re at the end of the year, when in the Gregorian calendar we remember and celebrate Christ’s incarnation—Christmas! So this post will serve as a bit of an update.
What’s been going on?
Code Hive Tx, LLC
I organized my consulting work as Code Hive Tx, LLC, with its own site https://codehivetx.us. I’m not pivoting into apiary work, although that is a potential future hobby. Instead, this is a hive for code: software development. It's a Texas Code Hive, headquartered in Dripping Springs, TX, USA where I have shared office space. Code Hive began its first consulting services January 2022.
CLDR Infrastructure
As mentioned in the srl.next post, I continue to work on Unicode’s Common Locale Data Repository (CLDR). A lot has happened, both in terms of project and data growth, but also in terms of process and software modernization. CLDR has had an emphasis on paying down technical debt, and much progress has been made. The crowdsourced linguistic voting platform has gone from a Java servlet-based structure to a modernized J2EE application, including OpenAPI Spec 3.0 (Swagger) REST documentation. The front end now has Vue3 as its core, largely replacing many home grown frameworks. Ansible was used to automate VM provisioning, with the result that an additional staging server was recently added, with almost no time spent in server configuration before it was ready to be productive.
Fintech
I’ve also picked up a local client in the fintech space, focussed around distributed computing and data science needs in python. I’ve brought in improvements to the automated build system as well as deploying custom Prometheus collectors and dashboards to make sure everything is working the way it ought to be. Actually, Prometheus figures somewhere into most of my projects, including telling me whether the home printer is accidentally powered off or not!
CLDR Keyboard Spec
Additionally, I’ve been involved in the CLDR Keyboard subcommittee for some time. As of this writing, there isn’t a great landing page with current status on this activity, although it’s on the TODO list. You can read the current landing page here.
In summary, the work of this subcommittee is to bring the UTS #35 Part 7 from its current state as merely describing keyboards, to become the standard industry-wide for implementing all keyboards. That is both ambitious, and also needs to be justified as a goal. I’m going to attempt to do both in a future post. Very briefly, though, currently keyboard development is completely platform-specific and so keyboard authors must convince the respective organizations and communities to independently develop for their language on Android, iOS, macOS, Linux, Windows, just to name a few.
What I did want to mention here is that many people have been volunteering their time, or been able to spend time on behalf of their respective organizations, in order to attend these subcommittee meetings over the past couple of years. However, that has not itself resulted in rapid development of the specification.
To that end, Code Hive Tx, LLC has received a Unicode Adopt-a-Character grant in order to progress the spec and fund participation in the meeting. As a result, I’ve been able to produce a draft specification with many improvements, as well as spend time on sample data, actual DTDs, test code, and so on. This enables the other team members to make comments on this spec work and has resulted in much progress.
But a spec without an implementation is, as they say, just a spec. That’s where Keyman comes in.
SIL Keyman
In addition to the spec work above, Code Hive Tx, LLC also has a contract with SIL International to add a production implementation of the CLDR Keyboard spec and associated tools to Keyman, SIL’s widely used open-source keyboard platform.
I recently returned from a week-long planning meeting in Siem Reap, Cambodia with the Keyman team. Besides an interesting trip and location itself, it was great to discuss in-person the future of keyboarding.
Next keystrokes
As mentioned above, the spec work and the implementation work go hand-in-hand, giving leverage to the prospect of a major sea change in ease of keyboard implementation. As of last week, we have the first actual keystrokes processed using a prototype CLDR keyboard. But that’s for another post: “Keyboard Progress”
Merry Christmas and Happy New Year from Code Hive Tx, LLC!
]]>
<p>Well, it was 2.5 years since I posted the <a href="/2020/07/16/srl-next/" title="srl.next">srl.next</a> article and clearly a lot has gon
git twofer, the thirdhttps://srl295.github.io/2022/04/26/git-twofer-3/2022-04-26T18:54:38.000Z2022-04-26T17:32:52.411ZAnother year, and another twofer. Same theme as TWOFER^ and TWOFER^^:
A couple of useful git commands. (Meaning: writing this down so that I don’t forget it!)
As before, these two are going to be given in the form of custom aliases. You can add the following to your ~/.gitconfig file or update the [alias] section of it exists.
I will cut right to the chase here: I put these in because of Eclipse .settings/ files.
I work on several Java+Maven projects that have historically used the Eclipse IDE. For most of them, Maven is now the source of truth. However, there are a number of settings such as tabs vs. spaces and indent style, which ought to be shared. How do we know which files should be checked in and which shouldn’t? There does not seem to be a good way to tell.
As I noted in this comment on CLDR-15048, there are many files, as well as .classpath, change quite often, seemingly due to:
mismatches in Eclipse versions as users upgrade or downgrade
plugins added/removed on the user’s side
using Eclipse vs. using VSCode Java (which is Eclipse inside)
Ugh, what is all of this? I was just trying to fix a typo in a comment!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
$ git status Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: UnicodeJsps/.settings/org.eclipse.core.resources.prefs modified: UnicodeJsps/.settings/org.eclipse.jdt.core.prefs modified: UnicodeJsps/.settings/org.eclipse.wst.common.component modified: UnicodeJsps/.settings/org.eclipse.wst.common.project.facet.core.xml modified: unicodetools/.project modified: unicodetools/.settings/org.eclipse.jdt.core.prefs
Untracked files: (use "git add <file>..." to include in what will be committed) unicodetools/.settings/org.eclipse.wst.common.component unicodetools/.settings/org.eclipse.wst.common.project.facet.core.xml
Note that some of these files don't seem to be automatically re-created by Eclipse when importing. So simply .gitignoreing some of the files doesn't work. We could ignore the entire .settings directory, but then each user could have potentially differing editor and other preferences.
skip-worktree to the rescue… it seems
Here is how I use git skip in practice. There are changes, but I want git to forget-about-them.
$ git status On branch cldr-14878/staging Your branch is up to date with 'srl295/cldr-14878/staging'.
Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: tools/cldr-apps/.settings/org.eclipse.jdt.core.prefs modified: tools/cldr-code/.settings/org.eclipse.jdt.core.prefs modified: tools/cldr-rdf/.settings/org.eclipse.jdt.core.prefs
no changes added to commit (use "git add" and/or "git commit -a")
$ ## Note: I have to skip files, not directories. git only knows files. $ git skip tools/cldr-apps/.settings/org.eclipse.jdt.core.prefs tools/cldr-rdf/.settings/org.eclipse.jdt.core.prefs tools/cldr-code/.settings/org.eclipse.jdt.core.prefs
$ git status On branch cldr-14878/staging Your branch is up to date with 'srl295/cldr-14878/staging'.
nothing to commit, working tree clean $ ## Clean! Now I can work with the files important to my task.
But there’s a catch
Let’s rebase this particular branch:
1 2 3 4 5 6 7 8
$ git rebase upstream/main error: Your local changes to the following files would be overwritten by checkout: tools/cldr-apps/.settings/org.eclipse.jdt.core.prefs tools/cldr-code/.settings/org.eclipse.jdt.core.prefs tools/cldr-rdf/.settings/org.eclipse.jdt.core.prefs Please commit your changes or stash them before you switch branches. Aborting error: could not detach HEAD
Oh no! Someone actually changed these files. OK, no problem, this happens all the time (I say to myself). I’ll just revert these changed files.
1 2 3 4
$ git checkout -- tools/cldr-apps/.settings/org.eclipse.jdt.core.prefs tools/cldr-code/.settings/org.eclipse.jdt.core.prefs tools/cldr-rdf/.settings/org.eclipse.jdt.core.prefs error: pathspec 'tools/cldr-apps/.settings/org.eclipse.jdt.core.prefs' did not match any file(s) known to git error: pathspec 'tools/cldr-code/.settings/org.eclipse.jdt.core.prefs' did not match any file(s) known to git error: pathspec 'tools/cldr-rdf/.settings/org.eclipse.jdt.core.prefs' did not match any file(s) known to git
Working as designed. Git doesn’t know anything about these files… 🙀
unskip
This is why there is an unskip command. We need to tell git to pay attention to these files again.
1 2 3
$ git unskip tools/cldr-apps/.settings/org.eclipse.jdt.core.prefs tools/cldr-code/.settings/org.eclipse.jdt.core.prefs tools/cldr-rdf/.settings/org.eclipse.jdt.core.prefs $ ## The files are now 'modified' again. But we can fix that: $ git checkout -- tools/cldr-apps/.settings/org.eclipse.jdt.core.prefs tools/cldr-code/.settings/org.eclipse.jdt.core.prefs tools/cldr-rdf/.settings/org.eclipse.jdt.core.prefs
OK, now the rebase can succeed!
1 2 3 4
$ git rebase upstream/main Auto-merging .github/workflows/ansible-lint.yml CONFLICT (content): Merge conflict in .github/workflows/ansible-lint.yml error: could not apply ac17b9bdff... ^ vagrant
Oops (this is a live demo!) well, it suceeded enough for me to deal with the substantive merge conflicts.
Of course, I can git skip files again when I want to.
Final notes
git update-index --skip-worktree and --unskip-worktree work on a single worktree only. So if you have several worktrees checked out, you can skip and unskip them individually. This skippage also is never propagated by a push or fetch.
One more thing - worktrees in action
We had a problem to solve. Some CLDR processes, such as comparing with past versions, needed to see ALL past releases of the project, checked out side–by–side. This was previously done by literally unzipping each release into a special folder. One idea to automate this was to have an automatic unzipper, or to check in all of the versions into yet another repository.
Instead, I wrote a Java tool which automates the use of git worktree.
org.unicode.cldr.tool.CheckoutArchive … Setting up in $ARCHIVE /Users/srl295/src/cldr-archive … # git worktree add /Users/srl295/src/cldr-archive/cldr-1.1 release-1-1 Preparing worktree (detached HEAD 9964598cd9) HEAD is now at 9964598cd9 CLDR-15567 v1.1 add a historic tag for release-1-1 including dtd from unicode.org # git worktree add /Users/srl295/src/cldr-archive/cldr-1.1.1 release-1-1-1 Preparing worktree (detached HEAD 07386be0f3) HEAD is now at 07386be0f3 This commit was manufactured by cvs2svn to create tag 'release-1-1-1'. # git worktree add /Users/srl295/src/cldr-archive/cldr-1.2 release-1-2 Preparing worktree (detached HEAD 504f0ecf2a) HEAD is now at 504f0ecf2a This commit was manufactured by cvs2svn to create tag 'release-1-2'. … $ git worktree list /Users/srl295/src/cldr 615221b7eb [cldr-14766/userreg] /Users/srl295/src/cldr-archive/cldr-1.1 9964598cd9 (detached HEAD) /Users/srl295/src/cldr-archive/cldr-1.1.1 07386be0f3 (detached HEAD) /Users/srl295/src/cldr-archive/cldr-1.2 504f0ecf2a (detached HEAD) /Users/srl295/src/cldr-archive/cldr-1.3 fb82e42152 (detached HEAD) /Users/srl295/src/cldr-archive/cldr-1.4 cb113490f3 (detached HEAD)
Since all version history is already in cldr/.git, it makes sense to leverage that into these 38 worktrees. Each worktree is checked out as a detached HEAD according to the release tag that produced it. This makes it very convenient to run tests and comparisons against the old versions.
Furthermore, unlike with an unzip, the full version history is available so git log, git blame, diffs and advanced searching is available to use.
]]>
<p>Another year, and another twofer. Same theme as <a href="/2021/03/29/git-twofer-2/" title="TWOFER^">TWOFER^</a> and <a href="/2019/09/09/
git twofer, againhttps://srl295.github.io/2021/03/29/git-twofer-2/2021-03-29T18:54:38.000Z2021-03-29T18:40:14.149ZTime for another twofer on git. As I wrote in the last twofer:
A couple of useful git commands. (Meaning: writing this down so that I don’t forget it!)
Of course, I did end up forgetting even that I had posted it to the blog. Oh well.
These two are going to be given in the form of custom aliases. You can add the following to your ~/.gitconfig file or update the [alias] section of it exists.
What’s inside? That’s always something I ask myself when contemplating a grocery store purchase. I find myself asking the same question when I’m about to rattle off git commit ; git push -f HEAD:prod and deploy some hopefully-tested code—or, at least send it off for PR review.
git diff-tree --no-commit-id --name-only -r fits the bill… try it out:
1 2
$ git ingredients HEAD # What's on the latest commit that I'm about to push? $ git ingredients fe4b8570 # What's on some specific commit?
git ingredients shows you a simple list of all of the files changed in the specific commit.
columbo
“…Just one more thing.” Before Job’s famous keynote-ender, there was Peter Falk.
Anyway, sometimes you think you’re done with a commit… but there’s just one more thing. A test you forgot to run. Whitespace. Rewrite the whole thing—it’s up to you.
git commit amend takes whatever is staged for commit, and merges it into the HEAD commit. Type it often enough, and an alias is in order. And just one more thing—if you just use amend, you will end up retaining the original date and time. Me, I like to bump the date to the time I last touched it.
git columbo will commit the currently staged files (if any), and give you the opportunity to edit the commit message.
git columbo -m 'fix all the things' lets you specify that message from the command line
git columbo somefile.p will only commit somefile.p among all the available files
git columbo -a One more thing: All the things! Commit everything you’ve changed.
I also run git columbo -S sometimes if I decide I want to sign the commit.
Credit here goes to the tweet/thread below. I added the --date=now part.
]]>
<p>Time for another twofer on git. As I wrote in the <a href="/2019/09/09/git-twofer/" title="last twofer">last twofer</a>:</p>
<blockquote>
srl.nexthttps://srl295.github.io/2020/07/16/srl-next/2020-07-16T07:00:00.000Z2020-07-20T21:10:28.000ZI’m a 2nd generation IBMer, from back when this meant “I’ve Been Moved.”
Fast forward to 1993. I knew that Taligent (also where my father was at that time) was working on a new OS of some kind, but that’s all I knew. (Pink). I just wanted to write some games for it*, and that needed an NDA. Instead of an NDA, I got a job: an internship, using my bran-new C++ skills.
Trying to do pre-build integration on an amazingly complex subsystem which somehow meshed with a dozen other subsystems was an interesting challenge, to say the least! (There were multi core builds all right—one keyboard and ADB mouse per core.)
I learned a lot about how to, and sometimes how not to, design OO systems, rubbing shoulders (and trading bug reports) with the best in the industry. Learned a lot, launched a lot of Nerf™ product, accidentally burned an OID (sorry)! … and, shipped some good features and even products. I also received plenty of constructive criticism.
I think my first job title was "Technical Specialist", probably because some form needed a title. Since the Apple tradition of design-your-own-businesscard was followed, I styled this as “TechnoSpecialist.” Later I graduated to Software Engineer or something, so I wrote “Code Sculptor.” I had in mind the idea of those who brought a certain craft to the field—Wozniak, Hertzfield, Atkinson, and so on.
I also ran into something called Unicode. I discovered it quite by accident. I still was trying to make some kind of game, but I decided (since I was in the NetComm group) to write a networked chat program. Sounds simple enough. The base text class was called TStandardText. To my surprise and annoyance, when I streamed a TStandardText (using operator>>= of course!), the other side received a bunch of NULLs (\0x00). A null, then a letter, a null, then another letter. And finally, TWO nulls to end it. For example, streaming ABC showed up on the wire not as ABC but as
1
\x00 \x41 \x00 \x42 \x00 \x43 \x00 \x00
When I read this into a char* on the server side, it had strlen() of 0. Huh? I plugged in a network analyzer (Network General Sniffer 10Base2), this being the NetComm lab, and it was confirmed. What happened to my string? Answer: Unicode. UCS-2 BE, to be precise.
I was not impressed. What was this Unicode® and why was it scrambling my text?? So, I just changed my chat program to ++ over every other null. Problem solved.
However, my attention was focused on networking and communications, protocol abstractions for streams and RPC, Object storage and network discovery (tcp port 6149, tal-pod).
I went on to work with email protocols, and then web services. I had run a very early departmental web server, and had done some prototyping. Around the time (1996-1997-1998) that Taligent was being folded into IBM as a wholly owned subsidiary, this turned into WebRunner ServerWorks and US 6,233,622 B1.
Also around that time, I took my first trip to Malta. Just before I went, I heard there was need to help on a “temporary assignment” to do some language related stuff. But it would be done by the time I got back from Malta, or so it was thought.
The work wasn't done, so I jumped in when i came back: A small team working on Bidi. Arabic and Hebrew text enablement. Somehow I understood a little more about Unicode by that time, and we got actually working worked.
If you haven't ever tried to implement Bidi text selection and rendering, try it. You'll either run away screaming, or… find a new favorite.
I had found my field. This “temporary” assignment (which wasn’t in itself as temporary as it was supposed to be) turned into a change of department at my request—a career change.
1997 also brought Java 1.1, including Taligent-contributed Unicode technology. I wasn't any part of that. (In 1996 I remembering handing out flyers for some “Taligent Analytics for Unicode”, Networld+interop NYC, but I'm sure I couldn't explain what it was for.)
However, soon after, I was helping out with what was released, in 1999 as the open source International Components for Unicode, partly based on the Java and C++ work, and available in C++ and Java.
Now, all of this global stuff needs some local data. The data directory of ICU kept getting bigger, and the bugs kept coming in. The data for ICU (and the JDK, and 100 Linux Locales) had all come from the ICIR data, from IBM Toronto. In 2003 a project was started, first under l18nux/LSB/FSG (what you now know and love as the Linux Foundation called CLDR.
It's an oversimplification, but from a pragmatic perspective, we took the ICU data subdirectory as a seed, split it off, put it in XML, and put a lot of process and tooling so that it could be easily compared with what all the other non-CLDR platforms were doing. And the comparisons showed that localization was all over the map… so to speak.
Anyway, a lot happened with ICU and CLDR over the years. I wrote the original Survey Tool to collect data for it, which today looks and acts nothing like my original version (and that's a very good thing).
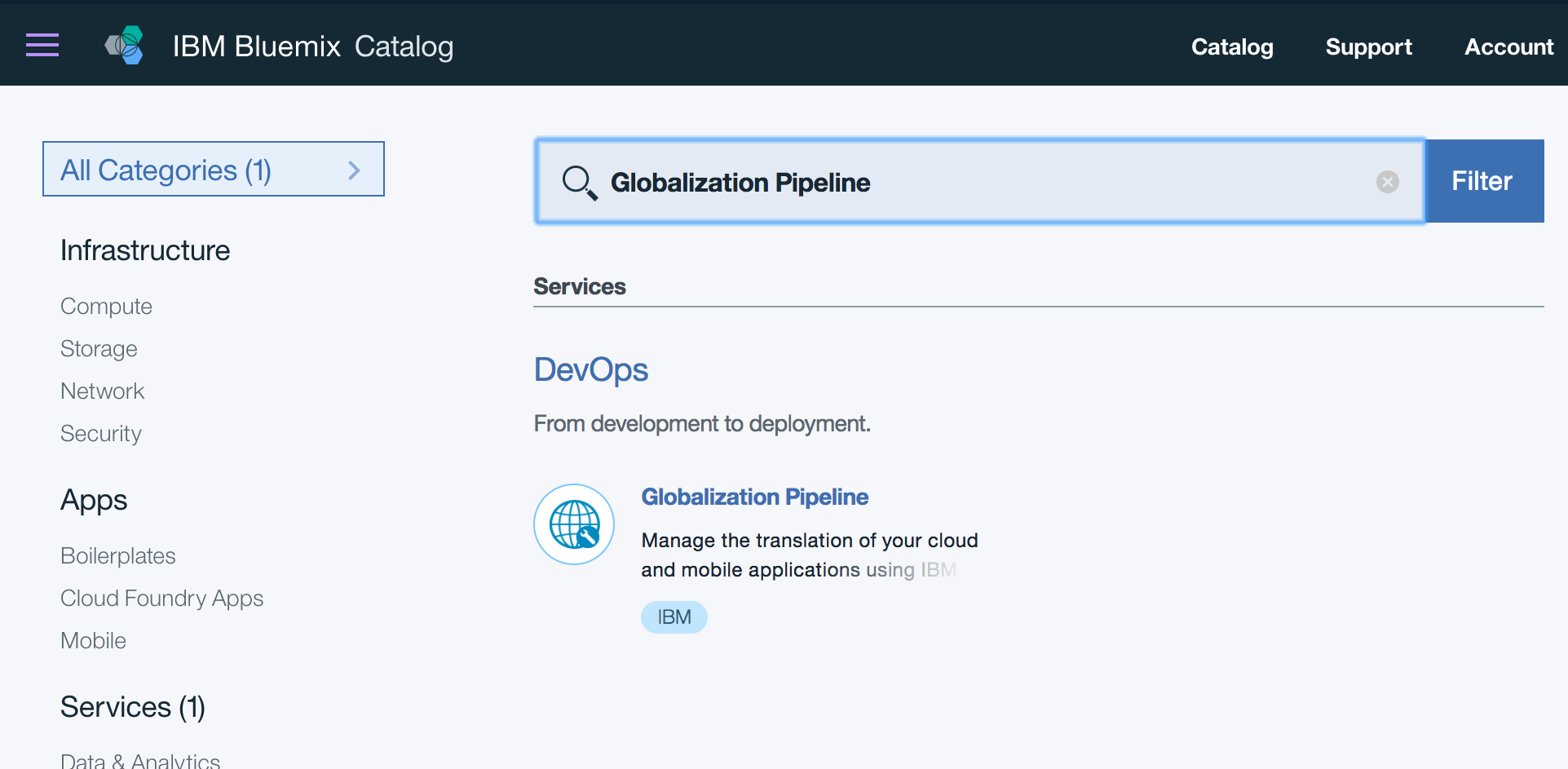
I also eventually got involved with translation, first by joining the XLIFF-TC (when I didn't actually do any translation nor use XLIFF), and only years later (in 2015) by being part of the team bringing you the Globalization Pipeline. ** on Bluemix (now IBM Cloud).
Learning about translation, actually using XLIFF, has been great. But, I found less and less time to work on core globalization. I had a short stint trying out the Project Management role, and also worked to bring OpenWhisk adoption up to speed in our group.
I mentioned being a 2nd generation IBMer. Not only that, I’m a second generation occupant of the same tower at the San José site that my father was in (not concurrently).
~23 years is a long time. One of our kids had said years back, “I want to help you work on Bluemix someday!” Well, Bluemix is now the IBM Cloud (go check it out!). That would be a third generation. I’m still proud to be an IBMer. However, come this Tuesday—right on the schedule that was presented to me—I won't be.
So what's next? Starting that same Tuesday, I'm going the independent contractor route. And my first contract is a short term one with Unicode itself, to work on CLDR!
So yes, I suppose the tweet above may count as a subtweet. CLDR is extremely important to how humans use computers intheir very own language and culture today, and I am excited to jump back in. What has become a “spare time project” will become literally my front burner work.
What's next?
Endnotes:
*I've never been much for playing or authoring games.
]]>
<p>I’m a 2nd generation IBMer, from back when this meant “I’ve Been Moved.”</p>
Sketch - how text workshttps://srl295.github.io/2020/01/16/sketch-how-text-works/2020-01-17T02:06:24.000Z2020-05-22T00:10:18.000ZJust a little sketch trying to explain how text works, fromthe brain of the sender to the brain of the recipient.
Work in progress of course.
]]>
<p>Just a little sketch trying to explain how text works, from
the brain of the sender to the brain of the recipient.</p>
<p>Work in progres
git twoferhttps://srl295.github.io/2019/09/09/git-twofer/2019-09-09T16:36:01.000Z2021-03-29T16:58:35.067ZA couple of useful git commands. (Meaning: writing this down so that I don’t forget it!)
remotes.group
I seem to have added a lot of remotes to some of my repos. Remotes are helpful for checking on the progressof different branches people are working on. But what if I want to git fetch --all but not really fetchall remotes? There has to be.. a better way.
1
$ git config remotes.dev "srl295 upstream"
Aha. Now I can do:
1
$ git fetch -p dev
And only the two “dev” remotes (srl295, my work, and upstream, the upstream fork) get updated.
worktree
I sometimes have several icu branches going at once. A git worktree allowsme to work on several branches without having to have unrelated (several gig of metadata) directories.
1 2
$ cd ~/src/icu $ git worktree add ../icu-64.2 release-64-2
Now ~/src/icu-64.2 contains a separate branch (or tag or whatever), but the objects (and LFS!) areall shared. When I’m done with it,
1 2
$ cd ~/src/icu $ git worktree remove ../icu-64.2
If I want to see what worktrees I have open, I can do this:
You can run the worktree commands from any of the worktrees. It’s like a happy git family ofworktrees!
Credit to Myles here:
]]>
<p>A couple of useful <code>git</code> commands. (Meaning: <em>writing this down so that I don’t forget it!</em>)</p>
<h2 id="remotes-group"
ICU Infrastructure Migrationhttps://srl295.github.io/2018/07/02/icu-infra/2018-07-03T01:24:54.000Z2020-05-22T00:10:18.000ZWell, it’s done. As of the end of the first half of 2018 I have exitted the role of primary infrastructure support for Unicode ICU, which I have had on and off since about 2002. (ICU has been open source since 1999, and the source code has roots going back even further.)
What I want to cover in this post is the actual migration process- see the ICU site for specifics about how to use the ICU repository and bug system. Note2 Here is a link to Unicode’s official blog post.
Note 1: In the first edition of this post, I didn't make a couple of things clear enough:
Teamwork — I did not accomplish all of the steps below alone. Thanks to all of the ICU-TC colleagues for helping with review and engineering tasks (that are still ongoing as I write this).
I’m not done with ICU — I remain a member of ICU-TC and I hope to actually contribute something again, now that my time isn’t spent “keeping the lights on.”
scoping the problem
The major two apects that needed migration were:
source code: 42,000 commits from Subversion to Git - hosted on GitHub (thanks!)
bugs: 13,000 bugs from trac to JIRA, hosted on the Atlassian cloud (thanks!)
Notice a repeated key word above: hosted.
Hosted mean that this role goes away. This is a continuation of a trend started a few years ago when I recycled 1,500+ pounds (680+ kg) of server equipment that used to be the ICU continuous build farm.
svn to git
Subversion to git may not sound like it should be particularly difficult, using subgit (thanks for the OSS license!) and others. However there are a number of mitigating factors.
Factor 1: Nonstandard svn tree use
If you have ever set up your own Subversion repo, you will be familiar with the top level trunk/branches/tags structure. You may also be aware that in svn (as is the UNIX way) “everything is a directory.” ICU had started with separate projects for icu4c and icu4j like so:
At some point in 2016 we decided that it was a good idea (and it was) to merge the trees. ICU for C and J are really developed together, and there is important interlock between the two regarding generated data files.
So far so good, but this point of discontinuity confuses the standard migration tools.
Factor 1c: accidental tree deletion
Mistakes happen. But, this one means it looks like all source was deleted and replaced.
Factor 2: large .jar files
Each .jar file ins't very big by itself. But ICU4J has a binary copy of its data file checked in. But there are thousands of copies of the icudata and other jars in the svn history. When all the dust settled, we probably end up with 2.3G of git lfs in 600 objects.
trac to JIRA
The trac to JIRA importer was not available to us (not available in JIRA cloud anymore). CSV import seemed very unwieldy, as we needed to be able to incrementally update the issues a we were developing the mapping. Plus, our trac instance has many customizations, with source patches (yes, contributed back where they made sense) and a custom plugin that powered our workflow.
solutions, tries, retries…
The ICU team has been seriouly discussing a move to some form of DVCS since early 2016.
in December 2017, with management approval to spend the necessary engineering time in 2018, I informed the ICU-TC:
By the end of 2Q2018, let's call it 2018-06-30T23:59:59.999Z, my infrastructure involvement in ICU needs to go to zero. This means no root logins…
Note, I'm only talking about infrastructure, not other project involvement.
By May, 2018 we had narrowed down what the future direction should look like.
In June 2018, the ICU-TC decided to go ahead with the migration as planned.
svn to git
Subgit works quite well. It takes some time, but it is worth it for a configurable conversion. However, it would not handle the discontinuities mentioned above.
I knew that Subversion has a dump format. Perhaps it would be possible to manipulate the dump, to make it look like ICU had always had a 'merged tree', and then import from there? ICU’s dumpfile is about 20 Gb.
I found some stack overflow questions that didn't quite match what I needed. I ran across SVN::DumpReloc in CPAN, and noted it for future reference. It didn’t work out of the box.
The challenge is that the svn dump is just a simple dump of the internal binary deltas. It does not take well to mkdir or copies with no intermediate dirs. So, simply renaming /icu/trunk/source/common/uloc.cpp to /trunk/icu4c/source/common/uloc.cpp in old revisions won’t work, because /trunk didn't exist until 2016.
node all the things?
As usual, I reached for npm init -q -y and started off to write a processor for the svn dump. I learned how to implement a Duplex stream, and got a little ways but definitely not far enough:
I tried to load the entire dumpfile into memory
I started in String space, assuming utf-8, whereas the svn dump is a mix of ASCII control headers (RFC 822) and binary blobs of arbitrary size.
And, it just plain didn’t work without making the dumpfile unloadable.
perl comes through (again)
I dusted off my perl pocket reference and even-dustier perl skills and set out to update SVN::DumpReloc. Unlike my js code, the perl actually worked. And working is good here.
In the end, it worked. A few bugs remained: branches and tags pre/post merge aren't quite where we want them. But the bulk of the svn history is kept.
JIRA and, bugs everywhere.
Given the above restrictions, I created a new node.js tool, https://github.com/unicode-org/icu-trac2jira to migrate a trac .sqlite3 dump to a JIRA database— by using the REST API. With a minimum of configuration it is able to map all of the fields, wiki syntax, and attachments needed to preserve our issue history. It's not perfect, and there's work to be done to fix some of the values, but I think it got the job done as far as initial migration.
The interesting thing, process-wise, is that I ended up with something that could run incrementally to update JIRA to match trac. So as there was feedback on errors in the wiki syntax conversion, I could re-run the tool over a subset of the tickets and it would either update a ticket, comment, etc. or cause no change depending on whether JIRA matched the expected results.
A separate script created 20,000 empty tickets in a block, before running this converter. This allowed us to keep the same ticket IDs between trac and jira.
In 2006 I migrated ICU from cvs and JitterBug to svn and trac. So yes, we've done this before!
JitterBug (which I also customized extensively and added new report CGIs to) had a very simple hierarchical file structure which was very hackable. Since trac used a sqlite database, I wrote source to read this file structure and emit SQL to recreate the bugs in the new form.
An oddity of that conversion is that I sort of punted on converting the date fields at all. Maybe there either wasn't a ticket-creation time, or the files had all been re-touched at some point. Or maybe it was just… laziness. Or whatever the other two are (I'd have to look it up).
Of course, our conversion process faithfully preserves this history. I think 1970-01-01T00:00:28.000Z is due to wanting a unique timestamp for some reason, thus (epoch time + 1 second per bug)-ish?
]]>
<p>Well, it’s done. As of <a href="https://time.is/2359_30_Jun_2018_in_UTC?SRL_icu-infrastructure_EOL" target="_blank" rel="noopener">the en
The Promise that Never Returnedhttps://srl295.github.io/2017/09/21/promise-never-returned/2017-09-22T02:12:50.000Z2020-05-22T00:10:18.000ZLet me tell you the story Of a Promise named Charlie, On an un Exceptional day. He put ten strings on the socket, reniced some child process then require('mbta')
Chorus Did he ever resolve, No he never resolved and his fate is still unsolv’d He’s been <pending> forever on that un-called closure He’s the Promise that never resolved
Charlie yielded his time somewhere down in libuv and he queued in th’event loop main. When he got called the constructor told him “one more bracket” Charlie couldn’t reach then() again
“Only one more build,” said the rock star coder “I’ll replace four lines with three” But, alas, git merge of the branch to master And the Promise sailed out to sea!
Oh the DevOps ninja Reboots the build in production Every day at quarter past two And through the open window Charlie’s newlines are sandwiched As the log goes rumbling through!
Lyrics: Steven R. Loomis 2017, Parody of: “M.T.A.” words by Jacqueline Steiner, Bess Lomax-Hawes (1949) which is itself based on “The Ship That Never Returned” by author and composer Henry Clay Work (1865).
]]>
<p>Let me tell you the story<br>
Of a Promise named Charlie,<br>
On an un Exceptional day.<br>
He put ten strings on the socket,<br>
reniced
Full Stack Language Enablementhttps://srl295.github.io/2017/06/06/full-stack-enablement/2017-06-06T16:04:49.000Z2020-05-22T00:10:18.000ZThis has been a working document for a while. I am publishing it here so that it can serve for more public discussion. Thank you to Co-authors: Anshuman Pandey, Isabelle Zaugg. Also thanks to others have discussed these items over the years such as Martin Raymond.
Edit 2018-07-10 I have added some further references at the end.
Introduction
There are a lot of steps to be taken in order to ensure that a language is fully supported. The objective of this document is to collect the steps needed and begin to plan how to accomplish them for particular languages. The intent is for this to serve as a guide to language community members and other interested parties in how to improve the support for a particular language.
Metrics
The diagram below shows languages in one axis, and the “stack” of support tasks on the other.
Coordination is key. Finding and communicating with the right people is often at least as difficult as the technical aspects. ScriptSource can be a good “central hub” to collect/publish information and needs for a user community.
Encoding
A critical step is of course Unicode encoding, but that is only the first step. Also, there can be (through no fault of anyone’s) a long gap between the first contact with a user community and the publication of a Unicode version supporting that language, not to mention other steps. The Script Encoding Initiative at UC Berkeley works closely with language communities working to encode their scripts in Unicode.
In the course of the encoding process, a lot of information is gathered which is relevant to other steps such as grammatical considerations and best practices around font and layout support.
Standardizing of the script ideally/typically happens before Unicode inclusion, but sometimes this can hold up Unicode inclusion, or be an ongoing challenge if it is incomplete after Unicode inclusion. Standardization of the script, as well as the orthography, are very helpful for digital vitality in general, as a standardized orthography helps “search” to work well, for example.
Font
From Martin Raymond:
One recommendation is to split the drawing of the glyphs from the more technical aspects of font design. Someone familiar with the writing can draw the letter shapes and pass them on to a font designer to develop the font.
In other words, the critical initial step is to get the correct glyphs from the user community.
Note that there is a need for fonts for different purposes: aesthetic, low resolution, small devices.
Layout
Determine if layout requirements are “complex” or not. (See the “shaping required” field of CLDR Script Metadata).
From website: “The W3C needs to make sure that the text layout and typographic needs of scripts and languages around the world are built in to technologies such as HTML, CSS, SVG, etc. so that Web pages and eBooks can look and behave as people expect around the world.”
The text-rendering tests can be useful to determine if OpenType font rendering is correct.
OS-level support
Desktop support
Mobile support (possibly even more important than desktop for global minority scripts)
Input
Keyboard
Virtual keyboards for mobile devices
Managing repertoire (Unihan, etc)
Transliteration standard into Latin script (This is helpful for input when a keyboard supporting the target script is unavailable.)
The development of many NLP applications requires large digital corpora, the collection of which is a project in itself. Even when corpora are collected, say through web crawling, when they are not available publicly, other developers cannot benefit from them as a resource. Therefore, a freely available repository of digital resources in a target language, to which contributors can add, is an ideal first step for the following efforts.
OCR
Spell checking
Auto-correction, Auto-suggestion, Auto-fill
Parsing & Stemming (helps search to happen with related terms)
Language glossaries/dictionaries/thesauri
Search capacity within word documents & pdfs
Translation: Ideally not just dominant language to minority language, but also minority to minority language (for maximum use within countries that enjoy a high level of language diversity)
Natural language queries and conversation
App-Level Support
This means going beyond:
Multilingual readiness (Unicode support: “Don’t garble my text”)
Leverage locale data and implementations (ICU, etc.)
Translation (above)
…to truly supporting language specific features. Some examples:
Arabic and East Asian advanced typography
NLP support as above
ICANN / IDN support
Support for a script within top-level domains allows an important level of localization online that breaks from the historically Latin-only top level domains and reflects the truly international nature of the Internet. ICANN has made significant progress in this area, and is currently in the process of working with language communities to define rules for using many new scripts in TLDs (top level domains).
Computer programming language in mother tongue
While this may seem a far-fetched dream today, the fact that programming languages are in English is a barrier to the full use of digital tools by much of the world’s population. This might be the final frontier for the internationalization/localization of digital technologies. “قلب” is an example of a programming language entirely in Arabic.
]]>
<p><em>This has been a working document for a while. I am publishing it here so that it can serve for more public discussion. Thank you to C
Announcing 🌲 pino-couchhttps://srl295.github.io/2017/06/02/pino-couch/2017-06-02T21:55:40.000Z2020-05-22T00:10:18.000Z
This little module is a transport which lets you capture your pino logs into any CouchDB database.
Why pino?
Speed: I haven’t independently tested the benchmarks, but I really like logging that doesn’t slow down the application. I want to be able to sprinkle logging generously in the application without slowing it down.
Simplicity: Take a look at the example below. We go from logging to the console, to logging in a database. The configuration and execution of log processing is entirely outside of the application.
Sticker: Because it has a logo that looks nice on a hex sticker? OK, not really. But @matteocollina presented this logger so effectively at NodeSummit, I asked for a sticker. Today, I’m glad to give something back to the community.
Taking it for a spin
First steps with pino
Let’s do a quick demo here, with a simple app that emits some logs:
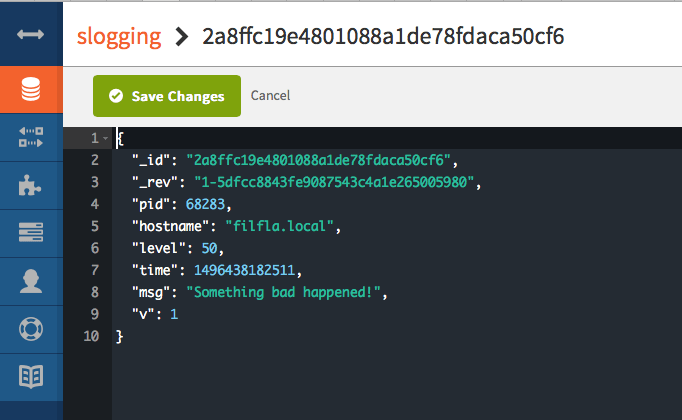
const pino = require('pino')(); pino.error('Something bad happened!'); pino.warn({ iToldYou: [ 'once', 'twice', 'thrice' ]}); pino.info({ msg: "Hey, check out these versions", versions: require('process').versions }); pino.trace('ALL THE DETAILS');
With the nice pino API you have lots of options for emitting logs.
1 2 3 4
$ node index.js {"pid":54534,"hostname":"filfla.local","level":50,"time":1496436803976,"msg":"Something bad happened!","v":1} {"pid":54534,"hostname":"filfla.local","level":40,"time":1496436803979,"iToldYou":["once","twice","thrice"],"v":1} {"pid":54534,"hostname":"filfla.local","level":30,"time":1496436803979,"msg":"Hey, check out these versions","versions":{"http_parser":"2.7.0","node":"8.0.0","v8":"5.8.283.41","uv":"1.11.0","zlib":"1.2.11","ares":"1.10.1-DEV","modules":"57","openssl":"1.0.2k","icu":"59.1","unicode":"9.0","cldr":"31.0.1","tz":"2017b"},"v":1}
Notice the trace() details were below the current level, so were omitted. This is detailed, but not super readable. If you are running something from the commadn line, the pino global utility tidies up the output nicely—in color, even, if your console supports it.
$ npm install -g pino $ node index.js | pino [2017-06-02T20:56:12.125Z] ERROR (56035 on filfla.local): Something bad happened! [2017-06-02T20:56:12.128Z] WARN (56035 on filfla.local): iToldYou: [ "once", "twice", "thrice" ] [2017-06-02T20:56:12.128Z] INFO (56035 on filfla.local): Hey, check out these versions versions: { "http_parser": "2.7.0", "node": "8.0.0", "v8": "5.8.283.41", "uv": "1.11.0", "zlib": "1.2.11", "ares": "1.10.1-DEV", "modules": "57", "openssl": "1.0.2k", "icu": "59.1", "unicode": "9.0", "cldr": "31.0.1", "tz": "2017b" }
Persistence without Perspiration: Relax!
Here’s where pino-couch comes in. I’m going to set up a https://cloudant.com databaseto store these logs (as I do in production), but you can also use a local or any other couchdb instance (as I do when developing locally).
First, create a database
Next, give appropriate permissions.
pino-couch only needs to write to the database, it doesn’t need to read. Click the Permissions tab, then Generate API Key. Choose only the _writer column for our new API key.
That’s actually it for configuration.
Start up our app, but using pino-couch. Use the APIKEY and PASSWORD that were generated above. And of course, your own ACCOUNT.
The output is about the same. We chained on a | pino at the end to keep the output human-readable— that's optional.
Let’s take a look at the Cloudant dashboard again:
There’s our data!
So now what?
Here are a couple of things you might do with your new logging pipeline:
Write a clever design document to mine your app logs for important stuff.
Even something as simple as the following will get you timestamp-ordered documents.
1 2 3
function (doc) { emit([newDate(doc.time).toISOString(),doc._id], doc.msg); }
Note that besides the time field with epoch time, hostname contains the current hostname. This is really useful for distinguishing logs from among a cluster of servers.
Ingest the data into Elasticsearch/Kibana
We’ve done this with great success. We were already pulling from another Cloudant DB, so it was easy to add the application logs.
And of course:
Relax
]]>
<p><a href="https://www.npmjs.com/package/pino-couch" target="_blank" rel="noopener"><img src="https://badge.fury.io/js/pino-couch.svg" alt=
Translating Kibana with the Globalization Pipelinehttps://srl295.github.io/2017/03/17/translating-kibana/2017-03-17T17:25:41.000Z2020-05-22T00:10:18.000Z
Introduction
This post (and video) will explain how to translate Kibana using the Globalization Pipeline service on Bluemix. Note that some of the steps shown here depend on kibana:8766 which was not merged as this article went to press. (Portions are based on the development-internationalization.asciidoc document from that PR.)
A Bluemix account to access Globalization Pipeline. It's free to sign up!
Java and the latest gp-cli.jar (Globalization Pipeline tools).
Setting up Globalization Pipeline
Follow the GP Quick Start Guide to create a service instance. Copy down the "credentials" into a new file, gp-credentials.json which should look something like the following:
Create the bundle on the GP instance. The example below uses English (en) as the source langage and requests Spanish, Japanese, and French targets (es,ja,fr).
1 2
$ java -jar {wherever}/gp-cli.jar create-bundle -j {wherever}/gp-credentials.json -b 'kibana_core' -l en,es,ja,fr A new bundle 'kibana_core' was successfully created.
The bundle will show up in the Bluemix dashboard under the service’s console, but as empty.
We are going to translate the src/core_plugins/kibana/translations/en.json file in Kibana. Upload that file to the Globalization Pipeline service using the command line:
1 2 3
$ cd ~/src/kibana $ java -jar {wherever}/gp-cli.jar import -j {wherever}/gp-credentials.json -b 'kibana_core' -l en -f src/core_plugins/kibana/translations/en.json -t json Resource data extracted from src/core_plugins/kibana/translations/en.json was successfully imported to bundle:kibana_core, language:en
If you head back over to the Bluemix dashboard, you can now see the populated bundle with translated content:
What you see was done with machine translation, hence the red “U” (Unreviewed). The content here can be corrected manually by clicking the Pencil icon, or marked as manually reviewed by clicking the Checkmark. It’s also possible to download the translated content for offline review or use, or to upload a corrected version of one of the translations.
Head back over to the command line, though, because it is time to create our plugin.
$ npm install -g yo generator-kibana-plugin … Everything looks all right!
$ yo kibana-plugin ? Your Plugin Name gp srl kibana plugin ? Short Description An awesome Kibana translation plugin ? Target Kibana Version master
I'm all done. Running npm install for you to install the required dependencies. If this fails, try running the command yourself.
You will notice that the generator has created a translations/es.json file. We will replace this with our translated content.
1
$ rm translations/es.json
Now, download the translated content into the correct files:
1 2 3 4 5 6 7 8
$ java -jar {wherever}/gp-cli.jar export -j {wherever}/gp-credentials.json -b 'kibana_core' -t json -l es -f translations/es.json Resource data exported from bundle:kibana_core, language: es was successfully saved to file translations/es.json
$ java -jar {wherever}/gp-cli.jar export -j {wherever}/gp-credentials.json -b 'kibana_core' -t json -l fr -f translations/fr.json Resource data exported from bundle:kibana_core, language: fr was successfully saved to file translations/fr.json
$ java -jar {wherever}/gp-cli.jar export -j {wherever}/gp-credentials.json -b 'kibana_core' -t json -l ja -f translations/ja.json Resource data exported from bundle:kibana_core, language: ja was successfully saved to file translations/ja.json
Update the index.js file in the plugin to mention the updated translations files.
Copy your entire translations plugin directory to the Kibana plugins (<kibana_root>/plugins/) directory
Trying it out
Fire up Kibana and you should see the translated content!
More steps
By the way, French isn’t included in the video or images becuase I ran into kibana#10580 during the production of this video. When this is fixed I will come back and edit this video, but until then, beware single quotes (') in your translated strings.
Note that if you repeat the import and export steps of the gp-cli tool, the Globalization Pipeline will automatically manage translation changes if, for example, translated keys are added or removed, or translated content changes.
Follow the progress of Kibana Globalization on Github: (kibana#6515).
Thanks to fellow IBMers Martin Hickey, Shikha Srivastava, and Jonathan Lo for the Kibana G11n work (kibana#6515), also the elastic/kibana team for being a great OSS community, and last but not least the entire Globalization Pipeline team.
]]>
<div class="video-container"><iframe src="//www.youtube.com/embed/fI9iuXWYHfI" frameborder="0" allowfullscreen></iframe></div>
<h1 id="Intr
Literate Programmershttps://srl295.github.io/2017/02/07/literate-programmers/2017-02-07T16:45:44.000Z2020-05-22T00:10:18.000ZBesides the Globalization Pipeline mug, one of my favorite coffee mugs says:
On the serious side, we need to emphasize communication skills in the technology industry. Even if I have a great idea, if I can’t communicate it, it will go nowhere. And neither will I.
Just to be clear, by “communication” I mean “talking with other humans”. Which brings me to today’s topic on the lighter side, and that is the overloading of English.Words such as function, overload, network, build all have specific meanings that weren’t originally found in Webster’s.The 1828 definition of computer, for example, is:
One who computes; a reckoner; a calculator.
In i18n, there are other words that have very specific meanings: global, globalization, collation, contraction, and of course locale, just to name a few.
To that end, I have started to add some tongue-in-cheek “redefinitions” to the bottom of the blog just to remind us all that these words have non-software meanings.
If you want to see them all without hitting reload an infinite number of times, you can see the original source here.
Speaking of i18n, this overloading doesn’t apply to English only. Most of my devices are set to es-US as their locale, so I see a lot of translated error message. gcc for example has a thriving translation project where dedicated persons cause “English” to be translated into, for example, “Spanish” such as:
#~ msgid "function ‘%D’ declared overloaded, but no definitions appear with which to resolve it?!?"
#~ msgstr "¿!¿se declaró la función ‘%D’ sobrecargada, pero no aparece ninguna definición con la cual resolverlo?!?"
Not sure why that’s ¿!¿ where I might expect ¿¡¿ — perhaps the initial ! just shows the compiler’s incredulity. In any event, sobrecargada seems to be a great cognate for overloaded. And with that, I will let you goto whatever you were doing before you started reading.
PR’s are welcome on my little list, or leave comments below. What are your favorite examples of overloaded terms, in any language?
]]>
<p>Besides the Globalization Pipeline mug, one of my favorite coffee mugs says:</p>
<img src="/2017/02/07/literate-programmers/IMG_0010.jpg"
Fallbacks in ICU4C Convertershttps://srl295.github.io/2017/02/02/icu4c-fallbacks/2017-02-03T00:05:26.000Z2020-05-22T00:10:18.000ZUnicode’s ICU version 59 is well underway at this point. While ideally everything would use Unicode, there still remains many systems — and much content — that is in non-Unicode encodings. For this reason, ICU, in both the C/C++ and the Java flavors, has rich support for codepage conversion.
One of many great features in ICU is the callback support. A lot can go wrong during codepage conversion, but in ICU, you can control what happens during exceptional situations.
Let’s try a simple sample. By the way, see the end of this post for hints on compiling the samples.
Substitute, Always
Our task is to convert black-bird (but with a U+00AD, “Soft Hyphen” in between the two words) to ASCII.
u_printf("Converted %d bytes\n", bytesWritten); for(int32_t i=0; i<bytesWritten; i++) { u_printf("\\x%02X ", bytes[i]&0xFF); } u_printf("\n"); // try to print it out on the console bytes[bytesWritten]=0; // terminate it first puts(bytes);
return0; // LocalUConverterPointer will cleanup cnv }
Hm. Ten characters in, nine out. What happened? Well, U+00AD is not a part of ASCII. ASCII is a seven bit encoding, thus only maps code points \x00 through \x7F inclusively. Furthermore, U+00AD is Default Ignorable, and as of ICU 54.1 (2014) in #10551, the soft hyphen can just be dropped.
But what if, for some reason, you don’t want the soft hyphen dropped? The pre ICU 54.1 behavior can be brought back easily with a custom call back. So, roll up your collective sleeves, and:
Great! Now, we are getting \x1A (ASCII SUB). It works.
When missing goes missing
A related question to the above has to do with converting from codepage to Unicode. That’s a better direction anyway. Convert to Unicode and stay there! One can hope. In any event…
For this task, we will convert 0x61, 0x80, 0x94, 0x4c, 0xea, 0xe5 from Shift-JIS to Unicode.
So, the letter "a" byte \x61 turned into U+0061, and then we have an illegal byte \x80 which turned into U+001A. Next, the valid sequence \x94 \x4c turns into U+732B which is 猫 (“cat”). Finally, the unmapped sequence \xea \xe5 turns into U+FFFD. Notice that the single byte illegal sequence turned into (SUB, U+001A), but the two byte sequence turned into U+FFFD. This is discussed somewhat here.
So far so good?
But what if you actually want U+FFFD as the substitution character for both sequences? This would be unexpected, but perhaps you have code that is particularly looking for U+FFFDs. We can write a similar callback:
To build these little snippets, I recommend the shell script icurun
If ICU is already installed in your appropriate paths, (visible to pkg-config or at least icu-config), you can simply run:
1
icurun some-great-app.cpp
… and icurun will compile and run a one-off.
If, however, you’ve built ICU yourself in some directory, you can instead use:
1
icurun -i path/to/your/icu some-great-app.cpp
… where path/to/you/icu is the full path to an ICU build or install directory.
If you are on windows… well, there isn’t a powershell version yet. Contributions welcome!
]]>
<p>Unicode’s <a href="http://icu-project.org" target="_blank" rel="noopener">ICU</a> version 59 is well underway at this point. While ideall
Globalization Pipeline for iOShttps://srl295.github.io/2017/01/06/g11n-pipeline-ios/2017-01-07T01:59:34.000Z2020-05-22T00:10:18.000ZYesterday we just tagged v1.0 of the Globalization Pipeline SDK for iOS. What can an iOS client do? Well, let’s build a simple app and find out.
Starting Out
First, I’ll launch XCode 8 and create a new workspace.
While that is launching, I’ll warn you that your author is only a recent graduate of the Swift playground, who once deployed some toy apps to a then-new iPhone 3GS. So, it’s been a while. Any suggestions for improvement are welcome. The actual SDK, however, was a team effort.
Today’s app will be a color mixer, to help artists mix their colors. You know, red and blue makes purple, and so on.
I will name the workspace gp-ios-color-mixer, and create a new single view app called GP Color Mixer. To simplify things, for now, I disable the checkbox “automatically manage signing.”
I want to include the new SDK. I’ll use Carthage to install it. Since I already have Homebrew installed, I only need to do
$ brew install carthage
Now I need a Cartfile that mentions the SDK. So I create one at the same level as my XCode project, containing:
github "IBM-Bluemix/gp-ios-client"
Following the Carthage instructions, I next run
$ carthage update
which results in
*** Fetching gp-ios-client*** Checking out gp-ios-client at "v1.0"*** xcodebuild output can be found in /var/folders/j9/yn_32djn36x4d4c2mvcr1kgm0000gn/T/carthage-xcodebuild.p2nKN2.log*** Building scheme "GPSDK" in TestFramework.xcworkspace
So far so good. Looking in the Finder, I now have GPSDK.framework right where I expect.
I’ll add it under “Linked frameworks and Libraries”.
We also need to make sure the framework is available at runtime. To do that, we add a build phase with a one-line script: /usr/local/bin/carthage copy-frameworks with a single input file - $(SRCROOT)/Carthage/Build/iOS/GPSDK.framework
Will it build? I add this to the top of my generated ViewController.swift:
1
import GPSDK
I mentioned turning off code signing, but I still ran into some odd warnings:
1 2 3 4 5
A shell task (/usr/bin/xcrun codesign --force --sign - --preserve-metadata=identifier,entitlements "/Users/srl/Library/Developer/Xcode/DerivedData/gp-ios-color-mixer-evyxcmilwuakdmdvxqqpmmnzisnn/Build/Products/Debug-iphonesimulator/GP Color Mixer.app/Frameworks/GPSDK.framework") failed with exit code 1: /Users/srl/Library/Developer/Xcode/DerivedData/gp-ios-color-mixer-evyxcmilwuakdmdvxqqpmmnzisnn/Build/Products/Debug-iphonesimulator/GP Color Mixer.app/Frameworks/GPSDK.framework: replacing existing signature /Users/srl/Library/Developer/Xcode/DerivedData/gp-ios-color-mixer-evyxcmilwuakdmdvxqqpmmnzisnn/Build/Products/Debug-iphonesimulator/GP Color Mixer.app/Frameworks/GPSDK.framework: resource fork, Finder information, or similar detritus not allowed
Command /bin/sh failed with exit code 1
Following QA1940 I was able to make some progress by running xattr -cr './Carthage/Build/iOS/GPSDK.framework'. Now, ⌘R Run rewards me with a blank app window and no errors. Let’s write some code!
Applying myself to the App
By code, of course, I mean a trip to the storyboard. Let's add a launch icon, because we can.
Now, I add some static fields, two picker views (for the input colors), and a button for action.
I wrote Color.swift to handle the color mixing. It will only support mixing from three of the primary colors - Red, Yellow, Blue. Any other mixing turns into muddy brown. Playground tested, ready to go.
enumColor : Int{ case red = 0, orange, yellow, green, blue, purple, muddy; // r+y = o, y+b = g, b+r = p funcsimpleDescription() -> String { switchself { case .red: return"red" case .orange: return"orange" case .yellow: return"yellow" case .green: return"green" case .blue: return"blue" case .purple: return"purple" case .muddy: return"muddy brown"// use this if we don't know how to mix a color // should be exhaustive } }
/** * Mix the colors, return the result */ funcmix( with: Color ) -> Color { if( self == .muddy || with == .muddy ) { return .muddy // anything + mud = mud } if( with == self ) { returnself// identity! } switchself { case .red: switch with { case .yellow: return .orange case .blue: return .purple default: return .muddy } case .yellow: switch with { case .red: return .orange case .blue: return .green default: return .muddy } case .blue: switch with { case .red: return .purple case .yellow: return .green default: return .muddy } default: return .muddy } } }
Time to wire it up. We create IBOutlets for each of the items. And, I’ll clear the result label just to verify that things are wired up. It runs OK, good.
Now, let’s set up the delegate stuff so that we can get the list of colors showing.
Hey, just a little more code and we’re feature complete!
1 2 3 4 5 6 7 8
@IBActionfuncdoMix(_ sender: Any) { let color1 = primaryColors[mixOne.selectedRow(inComponent: 0)] let color2 = primaryColors[mixTwo.selectedRow(inComponent: 0)]
let newColor = color1.mix(with: color2)
resultLabel.text = newColor.simpleDescription() }
At least, feature complete in English.
I’ll next take stock of the resource strings we need to have translated, so that we can run them through the Globalization Pipeline. I’ll call this gp-color-mixer.json
First, I create an instance of the Globalization Pipeline. The name you give the instance doesn’t matter here.
Now I create a bundle named gp-color-mixer. This name does matter, as our iOS app will use it to access the content.
I’ll Upload the gp-color-mixer.json file above as the source English content, choosing JSON format for the upload. I pick a few languages for the target.
If I view the bundle, I can see our strings there, as well as translated versions.
The Globalization Pipeline offers this web UI to manage content, as well as powerful REST APIs for managing the translation workflow. I need to grant access to the iOS app so that it can read but not modify the translations. So, switching over to the API Users tab…
The result of creating the API user is that some access information is shown, something like the following:
API User ID: 5726d656c6f6e7761746572Password: aHVudGVyNDIKInstance ID: 77617465726d656c6f6e77617465726dURL: https://something.something.bluemix.net/something/something
I take these and plug them into a new swift file named ReaderCredentials.swift like so: (this is a variant of ReaderCredentials-SAMPLE.swift in the SDK’s repo)
The iOS app will pick up changes if the translated content changes on the server. We could experiment with adding or removing languages, or updating translated keys.
Let me know if this works for you. This is my first post, and as I mentioned first app, in Swift so that’s a milestone. And, do let me know if^H^H what can be done to improve the sample app.
Thanks! Now go and make it global.
]]>
<p>Yesterday we just tagged v1.0 of the <a href="https://github.com/IBM-Bluemix/gp-ios-client" target="_blank" rel="noopener">Globalization
GP Client for JavaScript v1.3.0 releasedhttps://srl295.github.io/2016/12/07/g11n-pipeline-1-3-0/2016-12-08T00:43:08.000Z2020-05-22T00:10:18.000ZIt’s time for a refresh on the Globalization Pipeline Node.js client.I’ve just released v1.3.0 of this SDK.You can update your package.json the usual way, with npm install --save g11n-pipeline
I was able to increase function coverage to 100% thanks to the VSCode coverage plugin,and increase line coverage to 91%. Of course, when you test, you find bugs. Bugs such asrealizing that updateResourceStrings() was unusable because there wasno way to pass the languageId parameter.
Features
First of all, I synchronized the client with the latest current REST API. So take a peek at the docs againand see if there are any new features or fields.
I also tried to add some convenience functions. For example, getting the fulllist of language IDs supported used to require concatenating the source and targetlists. Now, with #40you can call .languages() on the Bundle object and it will build thislist for you. There is also a bundle.entries() accessor as of #14which returns ResourceEntry objects.
Speaking of convenience, most places where you used to call .someFunction({}, function callback(…){});the {} are optional. If it worked with {} before, it's now optional.
There are more features to add here, but I hope you like the changes in v1.3.0!
]]>
<p>It’s time for a refresh on the Globalization Pipeline Node.js client.
I’ve just released <a href="https://github.com/IBM-Bluemix/gp-js-cl
40th Internationalization and Unicode Conferencehttps://srl295.github.io/2016/11/05/iuc40/2016-11-05T05:33:58.000Z2020-05-22T00:10:18.000ZI'll start, and could almost end, my post with this tweet:
#IUC40 ended today. It was incredibly pleasing to see many old faces, and some new ones. Next up, #UTC149, next week. 🍷
Now that the conference is over, I’ll have to take some time to view slides from all of theother great presentations I missed whilegiving a personal record number of talks (long story), apart from the lightning talks which were apparently not recorded.
The conference, and Unicode in general, is about people. It is always great to see so manyfolks I've kept up with over the years… including of course my fellow IBMers frommany time zones away.
Off the top of my head, the important technical (besides personal) conversations I've had include:
]]>
<p>I'll start, and could almost end, my post with this tweet:</p>
<blockquote class="twitter-tweet" data-partner="tweetdeck"><p lang="en
gp-angular-client v1.2.0https://srl295.github.io/2016/10/07/gp-angular-client-v1-2-0/2016-10-07T20:41:47.000Z2020-05-22T00:10:18.000ZI just pushed out version 1.2.0 of our Angular Client for Globalization Pipelineto the usual places. gp-angular-client on bower, angular-g11n-pipeline on npm.
Thanks to IBMer @ckoberlein (GitHub) this SDK now supports variable substitution. So you can have a string such as Hello and translate and substitute this same string, so that for example in Spanish it will be Bienvenidos . So, output would be Hello Steven or Bienvenidos Steven depending on language.
]]>
<p>I just pushed out version 1.2.0 of our <a href="https://github.com/IBM-Bluemix/gp-angular-client" target="_blank" rel="noopener">Angular
source shibbolethhttps://srl295.github.io/2016/07/25/shibboleth/2016-07-25T23:28:15.000Z2020-05-22T00:10:18.000Z]]>
<img src="/2016/07/25/shibboleth/shibboleth.png" title="I’ll fire up code|emacs|vim and fix it.">
Translating ICU4C with Globalization Pipelinehttps://srl295.github.io/2016/07/14/Translating-ICU4C-with-Globalization-Pipeline/2016-07-14T23:57:01.000Z2020-05-22T00:10:18.000ZDisclaimer
This is a work in progress. If you read to the end, you’ll see wealmost reached our goal here.
Background
I work on ICU4C (the premier C/C++ library for Unicode support).And I work on Globalization Pipeline.These two haven’t really crossed paths… until now.
What we’ll do
This blog will cover how to use the Globalization Pipeline to translateuconv, one of ICU’s sample command line apps. We'll be translating the resourcefiles you can see in source/extra/uconv/resources
Gathering the tools
First, Download ICU4C source code (as a tarball or from the SVN repository) and compile it. See its readme for more details.
Now, set up Globalization Pipeline. See our Quick Start Guidefor getting your Globalization Pipeline instance created and set up.
In the GP dashboard, create a bundle named uconv. Select which languages you want to translate into, but don’t upload any strings. Click Save.
Also from the Bluemix dashboard, get the service credentials for your service. Save these in a file called mycreds.json that should look like theexample in this document.
We’ll also need the gp-cli java tool, so download the latest jar from gp-java-tools.
Note that we use the language tag en for English here, while the file was originally entitled root.This is because Globalization Pipeline works with the explicit source language, whereas for ICU, rootis what will be consulted as a fallback if no other languages are available.
It says it uploaded… but let’s check in the Globalization Pipeline dashboard:
OK! That’s great. Browsing over to the other language translations, we can see that the MT engines are hardat work. However, we happen to already have some French translationsin the ICU source base. We'll upload this, to overwrite some of the Machine-translatedentries for French:
Great. Now we have some human translated content as well. We cannow correct, upload/download content in the dashboard until we arehappy with the translations there.
Out of the Pipeline
OK, now for the next step- getting those translations back into ICU4C.
We can list the bundle status from the command line:
Still with me? Head back to the uconv/resources directory, and now run:
java -jar xliff.jar -s . -d . fr.xlf
And that brings us to…
1 2 3 4
Processing file: ./fr.xlf The XLIFF document is invalid, please check it first: Line 3, Column 81 Error: cvc-elt.1: No se ha encontrado la declaración del elemento 'xliff'.
Hrm. Seems like the XLIFF output isn't quite ready to be consumed.I filed a bug on this,of course.
Plan B
We're so close… let's see what we can do.What if we fetch the data in JSON format, and then hack up somethingto convert it to ICU format? It might suffice for this blog post.
Let's run the fetches again, but get JSON this time:
Now, run the following Node.js script over the JSON files:
node js2icu.js fr.json es.json …
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// js2icu.js const fs=require('fs'); const args = process.argv.slice(2); for (var i in args) { const f = args[i]; console.log('# read ' + f); const loc = f.split('.')[0]; const json = JSON.parse(fs.readFileSync(f)); var s = '\ufeff// -*- Coding: utf-8; -*-\n//auto converted\n' + loc + '\n{\n'; for (var k in json) { s = s + ' ' + k + ' { "' + json[k].replace(/"/g,'\\"') + '" }\n'; } s = s + '}\n'; console.log('# wrote ' + loc + '.txt'); fs.writeFileSync(loc+'.txt', s); }
You should be the proud owner of .txt files matching all of the languages you are using.
We're almost there. Let's go up and build uconv:
cd ..
Now edit resfiles.mk and change the RESSRC line to reference the new translations:
La conversión a Unicode de página de códigos falló en posición de byte de entrada de 0. Bytes: Error de cf: El carácter ilegal encontró La conversión a Unicode de página de códigos falló en posición de byte de entrada de 1. ……
Looks like we have a (more) translated uconv now.Some of the messages don’t quite work correctly due to ICU4C message conventions.Perhaps we will investigate this in the future.
]]>
<h1 id="Disclaimer"><a href="#Disclaimer" class="headerlink" title="Disclaimer"></a>Disclaimer</h1><p>This is a work in progress. If you rea
Perl on Bluemixhttps://srl295.github.io/2016/05/02/perl-on-bluemix/2016-05-02T23:17:14.000Z2020-05-22T00:10:18.000ZQuick Start
Marcus DelGreco at #FluentConf said something about perl support on platforms.I mentioned Bluemix allowed bring your own buildpack
Looking through the buildpack lists didn't turn up Perl per se but…
… enter sourcey-buildpack. It's a generic buildpack!From its README I knew I was in the right spot:
Isn't it simply amazing to see these demos, where they throw a bunch of php, ruby, Java or python code at a Cloud Foundry siteand it gets magically turned into a running web applications. Alas for me, life is often a wee bit more complicated than that.My projects always seem to required a few extra libraries or theyare even written in an dead scripting language like Perl.
The above builds perl (takes a while the first time) and deploys a little app that just dumps the deserialized JSON out.
Improving
But wait! It could be even simpler.So, I opened PRoetiker/sourcey-buildpack#2which adds a manifest file to the example. Then, only cf push is needed,the -b … option is now unnecessary.








 ]]>
]]>


 ]]>
]]>


 ]]>
]]>










")